
Spark with AWS
- AWS에서 Spark를 실행하기 위해서는 *EMR(Elastic MapReduce) 위에서 실행하는 것이 일반적
- *EMR?
- AWS의 Hadoop 서비스
- Hadoop(Yarn), Spark, Hive, Notebook 등이 설치되어 제공되는 서비스
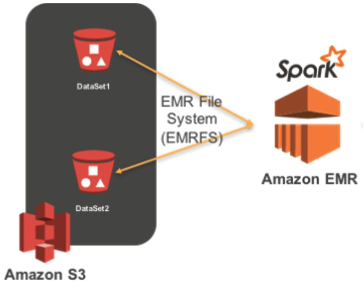
- EC2 서버들을 worker node로 사용하고 S3를 HDFS로 사용
- AWS 내의 다른 서비스와 연동이 쉽다!
- AWS의 Hadoop 서비스
Spark on EMR
- AWS의 EMR 클러스터 생성
- EMR 생성 시 Spark를 소프트웨어로 선택
생성 방법
- EMR 클러스터 생성
- EMR 콘솔로 이동 및 Create Cluster 선택
- Cluster Name 지정
- 소프트웨어 구성
- Spark가 포함된 EMR 릴리즈 선택
- Spark 및 필요 애플리케이션이 포함된 애플리케이션 선택
- 하드웨어 구성
- Master Node 선택 -> AWS의 Instance type
- Core Node 입력 -> Number of instances
- Create Cluster!
- Master Node 포트 설정
- EMR 클러스터 Summary 탭 -> Security groups for Master 선택
- Security Groups 페이지에서 마스터 노드의 security group ID를 클릭
- Edit inbound rules 버튼 클릭 후 Add rule 버튼 선택
- 포트번호로 22를 입력, Anywhere IPv4 선택, Save rules 버튼 선택
- 정상 실행 확인!
- Spark History Server 접속 및 확인
- Spark History Server 접속 및 확인
PySpark Job 실행 예제
- 입력 데이터를 S3로 로딩
- Stackoverflow 2022년 개발자 서베이 CSV 파일을 S3 버킷으로 업로드
- 경로 : 's3://spark-tutorial-dataset/survey_results_public.csv'
- 입력 데이터 ELT
- 입력 CSV 파일을 분석하여 결과를 S3에 다시 저장
- PySpark 잡 코드
from pyspark.sql import SparkSession from pyspark.sql.functions import col S3_DATA_INPUT_PATH = 's3://spark-tutorial-dataset/survey_results_public.csv' S3_DATA_OUTPUT_PATH = 's3://spark-tutorial-dataset/data-output' spark = SparkSession.builder.appName('Tutorial').getOrCreate() df = spark.read.csv(S3_DATA_INPUT_PATH, header=True) print('# of records {}'.format(df.count())) learnCodeUS = df.where((col('Country') == 'United States of America')).groupby('LearnCode').count() learnCodeUS.write.mode('overwrite').csv(S3_DATA_OUTPUT_PATH) # parquet learnCodeUS.show() print('Selected data is successfully saved to S3: {}'.format(S3_DATA_OUTPUT_PATH))
- PySpark 잡 실행 및 확인
- Spark 마스터 노드에 ssh로 로그인하여 spark-submit을 통해 실행
$ ssh -i {앞서 다운로드 받은 프라이빗 키}.pem hadoop@{마스터 노드 호스트 이름}$ spark-submit --master yarn stackoverflow.py
- S3에서 PySpark Job 실행 결과 확인
- Spark 마스터 노드에 ssh로 로그인하여 spark-submit을 통해 실행
'데이터 > Spark' 카테고리의 다른 글
| [Spark] 7. Partitioning & Bucketing (0) | 2024.12.03 |
|---|---|
| [Spark] 6. Spark Execution Plan (0) | 2024.12.03 |
| [Spark] 5. File Format (0) | 2024.12.03 |
| [Spark] 4. Database & Table (2) | 2024.12.03 |
| [Spark] 3. Spark SQL (0) | 2024.12.02 |